Enhance time sequence forecast efficiency with a method from sign processing
Modeling time sequence knowledge and forecasting it are complicated subjects. There are lots of methods that may very well be used to enhance mannequin efficiency for a forecasting job. We are going to talk about right here a method which will enhance the best way forecasting fashions soak up and make the most of time options, and generalize from them. The principle focus would be the creation of the seasonal options that feed the time sequence forecasting mannequin in coaching — there are simple good points to be made right here for those who embody the Fourier rework within the function creation course of.
This text assumes you might be conversant in the essential elements of time sequence forecasting — we won’t talk about this subject usually, however solely a refinement of 1 side of it. For an introduction to time sequence forecasting, see the Kaggle course on this subject — the approach mentioned right here builds on prime of their lesson on seasonality.
Take into account the Quarterly Australian Portland Cement manufacturing dataset, displaying the full quarterly manufacturing of Portland cement in Australia (in thousands and thousands of tonnes) from 1956:Q1 to 2014:Q1.
df = pd.read_csv('Quarterly_Australian_Portland_Cement_production_776_10.csv', usecols=['time', 'value'])
# convert time from yr float to a correct datetime format
df['time'] = df['time'].apply(lambda x: str(int(x)) + '-' + str(int(1 + 12 * (x % 1))).rjust(2, '0'))
df['time'] = pd.to_datetime(df['time'])
df = df.set_index('time').to_period()
df.rename(columns={'worth': 'manufacturing'}, inplace=True)
manufacturing
time
1956Q1 0.465
1956Q2 0.532
1956Q3 0.561
1956Q4 0.570
1957Q1 0.529
... ...
2013Q1 2.049
2013Q2 2.528
2013Q3 2.637
2013Q4 2.565
2014Q1 2.229[233 rows x 1 columns]

That is time sequence knowledge with a development, seasonal elements, and different attributes. The observations are made quarterly, spanning a number of a long time. Let’s check out the seasonal elements first, utilizing the periodogram plot (all code is included within the companion pocket book, linked on the finish).

The periodogram reveals the facility density of spectral elements (seasonal elements). The strongest part is the one with a interval equal to 4 quarters, or 1 yr. This confirms the visible impression that the strongest up-and-down variations within the graph occur about 10 instances per decade. There may be additionally a part with a interval of two quarters — that’s the identical seasonal phenomenon, and it merely means the 4-quarter periodicity isn’t a easy sine wave, however has a extra complicated form. We are going to ignore elements with durations greater than 4, for simplicity.
Should you attempt to match a mannequin to this knowledge, maybe in an effort to forecast the cement manufacturing for instances past the tip of the dataset, it could be a good suggestion to seize this yearly seasonality in a function or set of options, and supply these to the mannequin in coaching. Let’s see an instance.
Seasonal elements might be modeled in a lot of alternative ways. Usually, they’re represented as time dummies, or as sine-cosine pairs. These are artificial options with a interval equal to the seasonality you’re attempting to mannequin, or a submultiple of it.
Yearly time dummies:
seasonal_year = DeterministicProcess(index=df.index, fixed=False, seasonal=True).in_sample()
print(seasonal_year)
s(1,4) s(2,4) s(3,4) s(4,4)
time
1956Q1 1.0 0.0 0.0 0.0
1956Q2 0.0 1.0 0.0 0.0
1956Q3 0.0 0.0 1.0 0.0
1956Q4 0.0 0.0 0.0 1.0
1957Q1 1.0 0.0 0.0 0.0
... ... ... ... ...
2013Q1 1.0 0.0 0.0 0.0
2013Q2 0.0 1.0 0.0 0.0
2013Q3 0.0 0.0 1.0 0.0
2013Q4 0.0 0.0 0.0 1.0
2014Q1 1.0 0.0 0.0 0.0[233 rows x 4 columns]
Yearly sine-cosine pairs:
cfr = CalendarFourier(freq='Y', order=2)
seasonal_year_trig = DeterministicProcess(index=df.index, seasonal=False, additional_terms=[cfr]).in_sample()
with pd.option_context('show.max_columns', None, 'show.expand_frame_repr', False):
print(seasonal_year_trig)
sin(1,freq=A-DEC) cos(1,freq=A-DEC) sin(2,freq=A-DEC) cos(2,freq=A-DEC)
time
1956Q1 0.000000 1.000000 0.000000 1.000000
1956Q2 0.999963 0.008583 0.017166 -0.999853
1956Q3 0.017166 -0.999853 -0.034328 0.999411
1956Q4 -0.999963 -0.008583 0.017166 -0.999853
1957Q1 0.000000 1.000000 0.000000 1.000000
... ... ... ... ...
2013Q1 0.000000 1.000000 0.000000 1.000000
2013Q2 0.999769 0.021516 0.043022 -0.999074
2013Q3 0.025818 -0.999667 -0.051620 0.998667
2013Q4 -0.999917 -0.012910 0.025818 -0.999667
2014Q1 0.000000 1.000000 0.000000 1.000000[233 rows x 4 columns]
Time dummies can seize very complicated waveforms of the seasonal phenomenon. On the flip facet, if the interval is N, then you definitely want N time dummies — so, if the interval could be very lengthy, you will have numerous dummy columns, which is probably not fascinating. For non-penalized fashions, typically simply N-1 dummies are used — one is dropped to keep away from collinearity points (we’ll ignore that right here).
Sine/cosine pairs can mannequin arbitrarily very long time durations. Every pair will mannequin a pure sine waveform with some preliminary section. Because the waveform of the seasonal function turns into extra complicated, you will have so as to add extra pairs (improve the order of the output from CalendarFourier).
(Aspect word: we use a sine/cosine pair for every interval we need to mannequin. What we actually need is only one column of A*sin(2*pi*t/T + phi) the place A is the burden assigned by the mannequin to the column, t is the time index of the sequence, and T is the part interval. However the mannequin can not modify the preliminary section phi whereas becoming the info — the sine values are pre-computed. Fortunately, the system above is equal to: A1*sin(2*pi*t/T) + A2*cos(2*pi*t/T) and the mannequin solely wants to seek out the weights A1 and A2.)
TLDR: What these two methods have in widespread is that they characterize seasonality through a set of repetitive options, with values that cycle as typically as as soon as per the time interval being modeled (time dummies, and the bottom sine/cosine pair), or a number of instances per interval (greater order sine/cosine). And every certainly one of these options has values various inside a set interval: from 0 to 1, or from -1 to 1. These are all of the options we’ve got to mannequin seasonality right here.
Let’s see what occurs after we match a linear mannequin on such seasonal options. However first, we have to add development options to the options assortment used to coach the mannequin.
Let’s create development options after which be a part of them with the seasonal_year time dummies generated above:
trend_order = 2
trend_year = DeterministicProcess(index=df.index, fixed=True, order=trend_order).in_sample()
X = trend_year.copy()
X = X.be a part of(seasonal_year)
const development trend_squared s(1,4) s(2,4) s(3,4) s(4,4)
time
1956Q1 1.0 1.0 1.0 1.0 0.0 0.0 0.0
1956Q2 1.0 2.0 4.0 0.0 1.0 0.0 0.0
1956Q3 1.0 3.0 9.0 0.0 0.0 1.0 0.0
1956Q4 1.0 4.0 16.0 0.0 0.0 0.0 1.0
1957Q1 1.0 5.0 25.0 1.0 0.0 0.0 0.0
... ... ... ... ... ... ... ...
2013Q1 1.0 229.0 52441.0 1.0 0.0 0.0 0.0
2013Q2 1.0 230.0 52900.0 0.0 1.0 0.0 0.0
2013Q3 1.0 231.0 53361.0 0.0 0.0 1.0 0.0
2013Q4 1.0 232.0 53824.0 0.0 0.0 0.0 1.0
2014Q1 1.0 233.0 54289.0 1.0 0.0 0.0 0.0[233 rows x 7 columns]
That is the X dataframe (options) that shall be used to coach/validate the mannequin. We’re modeling the info with quadratic development options, plus the 4 time dummies wanted for the yearly seasonality. The y dataframe (goal) shall be simply the cement manufacturing numbers.
Let’s carve a validation set out of the info, containing the yr 2010 observations. We are going to match a linear mannequin on the X options proven above and the y goal represented by cement manufacturing (the check portion), after which we’ll consider mannequin efficiency in validation. We may also do all the above with a trend-only mannequin that may solely match the development options however ignores seasonality.
def do_forecast(X, index_train, index_test, trend_order):
X_train = X.loc[index_train]
X_test = X.loc[index_test]y_train = df['production'].loc[index_train]
y_test = df['production'].loc[index_test]
mannequin = LinearRegression(fit_intercept=False)
_ = mannequin.match(X_train, y_train)
y_fore = pd.Sequence(mannequin.predict(X_test), index=index_test)
y_past = pd.Sequence(mannequin.predict(X_train), index=index_train)
trend_columns = X_train.columns.to_list()[0 : trend_order + 1]
model_trend = LinearRegression(fit_intercept=False)
_ = model_trend.match(X_train[trend_columns], y_train)
y_trend_fore = pd.Sequence(model_trend.predict(X_test[trend_columns]), index=index_test)
y_trend_past = pd.Sequence(model_trend.predict(X_train[trend_columns]), index=index_train)
RMSLE = mean_squared_log_error(y_test, y_fore, squared=False)
print(f'RMSLE: {RMSLE}')
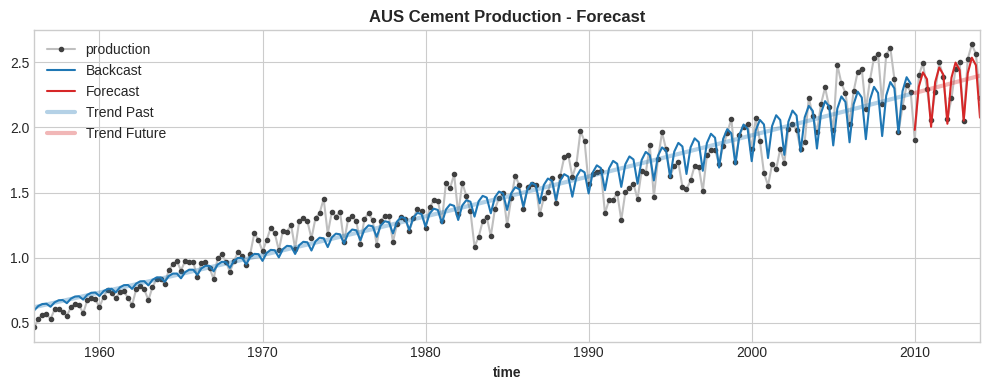
ax = df.plot(**plot_params, title="AUS Cement Manufacturing - Forecast")
ax = y_past.plot(colour="C0", label="Backcast")
ax = y_fore.plot(colour="C3", label="Forecast")
ax = y_trend_past.plot(ax=ax, colour="C0", linewidth=3, alpha=0.333, label="Development Previous")
ax = y_trend_fore.plot(ax=ax, colour="C3", linewidth=3, alpha=0.333, label="Development Future")
_ = ax.legend()
do_forecast(X, index_train, index_test, trend_order)
RMSLE: 0.03846449744356434

Blue is prepare, purple is validation. The total mannequin is the sharp, skinny line. The trend-only mannequin is the huge, fuzzy line.
This isn’t dangerous, however there may be one obvious difficulty: the mannequin has discovered a constant-amplitude yearly seasonality. Although the yearly variation truly will increase in time, the mannequin can solely stick with fixed-amplitude variations. Clearly, it is because we gave the mannequin solely fixed-amplitude seasonal options, and there’s nothing else within the options (goal lags, and many others) to assist it overcome this difficulty.
Let’s dig deeper into the sign (the info) to see if there’s something there that might assist with the fixed-amplitude difficulty.
The periodogram will spotlight all spectral elements within the sign (all seasonal elements within the knowledge), and can present an outline of their general energy, nevertheless it’s an combination, a sum over the entire time interval. It says nothing about how the amplitude of every seasonal part could fluctuate in time throughout the dataset.
To seize that variation, you need to use the Fourier spectrogram as a substitute. It’s just like the periodogram, however carried out repeatedly over many time home windows throughout your complete knowledge set. Each periodogram and spectrogram can be found as strategies within the scipy library.
Let’s plot the spectrogram for the seasonal elements with durations of two and 4 quarters, talked about above. As at all times, the total code is within the companion pocket book linked on the finish.
spectrum = compute_spectrum(df['production'], 4, 0.1)
plot_spectrogram(spectrum, figsize_x=10)

What this diagram reveals is the amplitude, the “energy” of the 2-quarter and 4-quarter elements over time. They’re fairly weak initially, however change into very sturdy round 2010, which matches the variations you may see within the knowledge set plot on the prime of this text.
What if, as a substitute of feeding the mannequin fixed-amplitude seasonal options, we modify the amplitude of those options in time, matching what the spectrogram tells us? Would the ultimate mannequin carry out higher in validation?
Let’s decide the 4-quarter seasonal part. We might match a linear mannequin (referred to as the envelope mannequin) on the order=2 development of this part, on the prepare knowledge (mannequin.match()), and prolong that development into validation / testing (mannequin.predict()):
envelope_features = DeterministicProcess(index=X.index, fixed=True, order=2).in_sample()spec4_train = compute_spectrum(df['production'].loc[index_train], max_period=4)
spec4_train
spec4_model = LinearRegression()
spec4_model.match(envelope_features.loc[spec4_train.index], spec4_train['4.0'])
spec4_regress = pd.Sequence(spec4_model.predict(envelope_features), index=X.index)
ax = spec4_train['4.0'].plot(label="part envelope", colour="grey")
spec4_regress.loc[spec4_train.index].plot(ax=ax, colour="C0", label="envelope regression: previous")
spec4_regress.loc[index_test].plot(ax=ax, colour="C3", label="envelope regression: future")
_ = ax.legend()

The blue line is the energy of the variation of the 4-quarter part within the prepare knowledge, fitted as a quadratic development (order=2). The purple line is identical factor, prolonged (predicted) over the validation knowledge.
We’ve got modeled the variation in time of the 4-quarter seasonal part. We will take the output from the envelope mannequin, and multiply it by the point dummies akin to the 4-quarter seasonal part:
spec4_regress = spec4_regress / spec4_regress.imply()season_columns = ['s(1,4)', 's(2,4)', 's(3,4)', 's(4,4)']
for c in season_columns:
X[c] = X[c] * spec4_regress
print(X)
const development trend_squared s(1,4) s(2,4) s(3,4) s(4,4)
time
1956Q1 1.0 1.0 1.0 0.179989 0.000000 0.000000 0.000000
1956Q2 1.0 2.0 4.0 0.000000 0.181109 0.000000 0.000000
1956Q3 1.0 3.0 9.0 0.000000 0.000000 0.182306 0.000000
1956Q4 1.0 4.0 16.0 0.000000 0.000000 0.000000 0.183581
1957Q1 1.0 5.0 25.0 0.184932 0.000000 0.000000 0.000000
... ... ... ... ... ... ... ...
2013Q1 1.0 229.0 52441.0 2.434701 0.000000 0.000000 0.000000
2013Q2 1.0 230.0 52900.0 0.000000 2.453436 0.000000 0.000000
2013Q3 1.0 231.0 53361.0 0.000000 0.000000 2.472249 0.000000
2013Q4 1.0 232.0 53824.0 0.000000 0.000000 0.000000 2.491139
2014Q1 1.0 233.0 54289.0 2.510106 0.000000 0.000000 0.000000[233 rows x 7 columns]
The 4 time dummies aren’t both 0 or 1 anymore. They’ve been multiplied by the part envelope, and now their amplitude varies in time, similar to the envelope.
Let’s prepare the principle mannequin once more, now utilizing the modified time dummies.
do_forecast(X, index_train, index_test, trend_order)
RMSLE: 0.02546321729737165

We’re not aiming for an ideal match right here, since that is only a toy mannequin, nevertheless it’s apparent the mannequin performs higher, it’s extra intently following the 4-quarter variations within the goal. The efficiency metric has improved additionally, by 51%, which isn’t dangerous in any respect.
Bettering mannequin efficiency is an enormous subject. The conduct of any mannequin doesn’t rely upon a single function, or on a single approach. Nonetheless, for those who’re seeking to extract all you may out of a given mannequin, it is best to in all probability feed it significant options. Time dummies, or sine/cosine Fourier pairs, are extra significant after they mirror the variation in time of the seasonality they’re modeling.
Adjusting the seasonal part’s envelope through the Fourier rework is especially efficient for linear fashions. Boosted timber don’t profit as a lot, however you may nonetheless see enhancements virtually it doesn’t matter what mannequin you utilize. Should you’re utilizing a hybrid mannequin, the place a linear mannequin handles deterministic options (calendar, and many others), whereas a boosted timber mannequin handles extra complicated options, it is necessary that the linear mannequin “will get it proper”, due to this fact leaving much less work to do for the opposite mannequin.
It’s also essential that the envelope fashions you utilize to regulate seasonal options are solely educated on the prepare knowledge, and they don’t see any testing knowledge whereas in coaching, similar to every other mannequin. When you modify the envelope, the time dummies include data from the goal — they don’t seem to be purely deterministic options anymore, that may be computed forward of time over any arbitrary forecast horizon. So at this level data might leak from validation/testing again into coaching knowledge for those who’re not cautious.
The information set used on this article is obtainable right here below the Public Area (CC0) license:
The code used on this article might be discovered right here:
A pocket book submitted to the Retailer Gross sales — Time Sequence Forecasting competitors on Kaggle, utilizing concepts described on this article:
A GitHub repo containing the event model of the pocket book submitted to Kaggle is right here:
All pictures and code used on this article are created by the creator.














{kind=link}